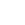 Jetzt anfragen
Jetzt anfragenEin Ausfall von Systemen kann signifikante Auswirkungen haben. Eine Fehlkonfiguration in einem zentralen System von Facebook bedeutete kürzlich den kompletten Ausfall aller Facebook-Dienste. Dies sorgte nicht nur zu viel weltweiter Verwirrung – in vielen Entwicklungsländern bedeutete der Ausfall massive Einschnitte im täglichen Leben. Ein Grund für die weitreichenden Folgen mancher Systemausfälle ist, dass Unternehmen sich nicht genug damit beschäftigen wie sich ein System in Ausnahmesituationen verhält. Die stark gestiegene Verteilung von Systemen auf verschiedene Dienste und Softwarekomponenten potenziert dieses Problem noch zusätzlich, wie das genannte Facebook-Beispiel zeigt.
Der Anfang November von Microsoft vorgestellte Dienst “Azure Chaos Studio” soll dabei helfen, die Systemstabilität in Ausnahmesituationen zu validieren. Durch verschiedene Tests soll sichergestellt werden, dass das System stabil bleibt oder zumindest eingeschränkt weiter funktioniert. Das Durchführen solcher Tests wird oft auch als Chaos Engineering beschrieben, initial geprägt durch die Chaos Monkeys bei Netflix. Für allgemeine Informationen zu diesem Thema lohnt auch ein Blick auf den Abschnitt zu Chaos Engineering in Microsofts Architekturempfehlungen. In diesem Blogpost wird vor allem ein erster Blick auf den vorgestellten Dienst geworfen.
Experimente und deren Ziele
Azure Chaos Studio besteht aktuell im Kern aus zwei Teilen: “Experiments” beschreiben die Szenarien, welche getestet werden sollen. Ziele (“Targets”) beschreiben die Ressourcen, auf welchen getestet werden kann. Bevor beispielsweise auf einer virtuellen Maschine ein Experiment durchgeführt werden kann, muss die Maschine erst grundsätzlich für Tests freigegeben werden. Außerdem können die möglichen Fehlerszenarien (“Faults”) pro Ressource granular bestimmt werden. Dadurch ist beispielsweise möglich, produktive Ressourcen nicht für Tests freizugeben oder nur für einen Teil der Fehlerfälle freizugeben.
Viele Ressourcen stehen nicht für Experimente zur Verfügung
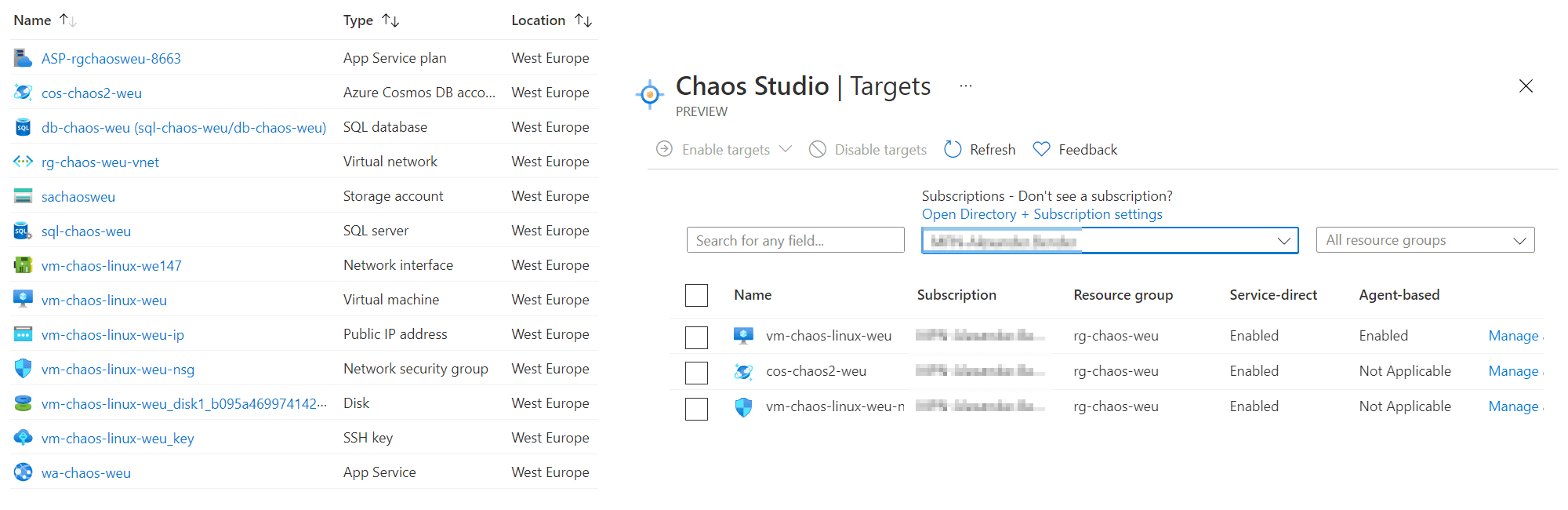
Bei dieser Auswahl zeigt sich eine der größten Einschränkungen der aktuellen Preview-Version: Von unserer beispielhaft zusammengestellten Systemlandschaft wird nur ein Bruchteil der Ressourcen unterstützt. Bei den verfügbaren Zielen liegt der Fokus aktuell auf Infrastructure-as-a-Service-Diensten wie virtuellen Maschinen. Software-as-a-Service-Dienste wie CosmosDB und Redis stellen die Ausnahme dar. Zusätzlich muss bei den Zielen zwischen “Agent-based” und “Service-based” unterschieden werden. Für ersteres wird eine Microsoft-Software auf den Systemen installiert um die Experimente auszuführen, während letztere komplett von außen auf die Ressourcen zugreifen. Vor allem die Service-basierten Fehlerfälle kann man also auch leicht selbst provozieren, Azure Chaos Studio bietet hier primär die Orchestrierung. Die Zugriffsberechtigungen auf die Systeme laufen dabei komplett über Managed Identity, das Verwalten von Secrets entfällt.
Für viele Fehlerszenarien muss zusätzliche Software auf den Systemen installiert werden
Experimente erstellen und ausführen
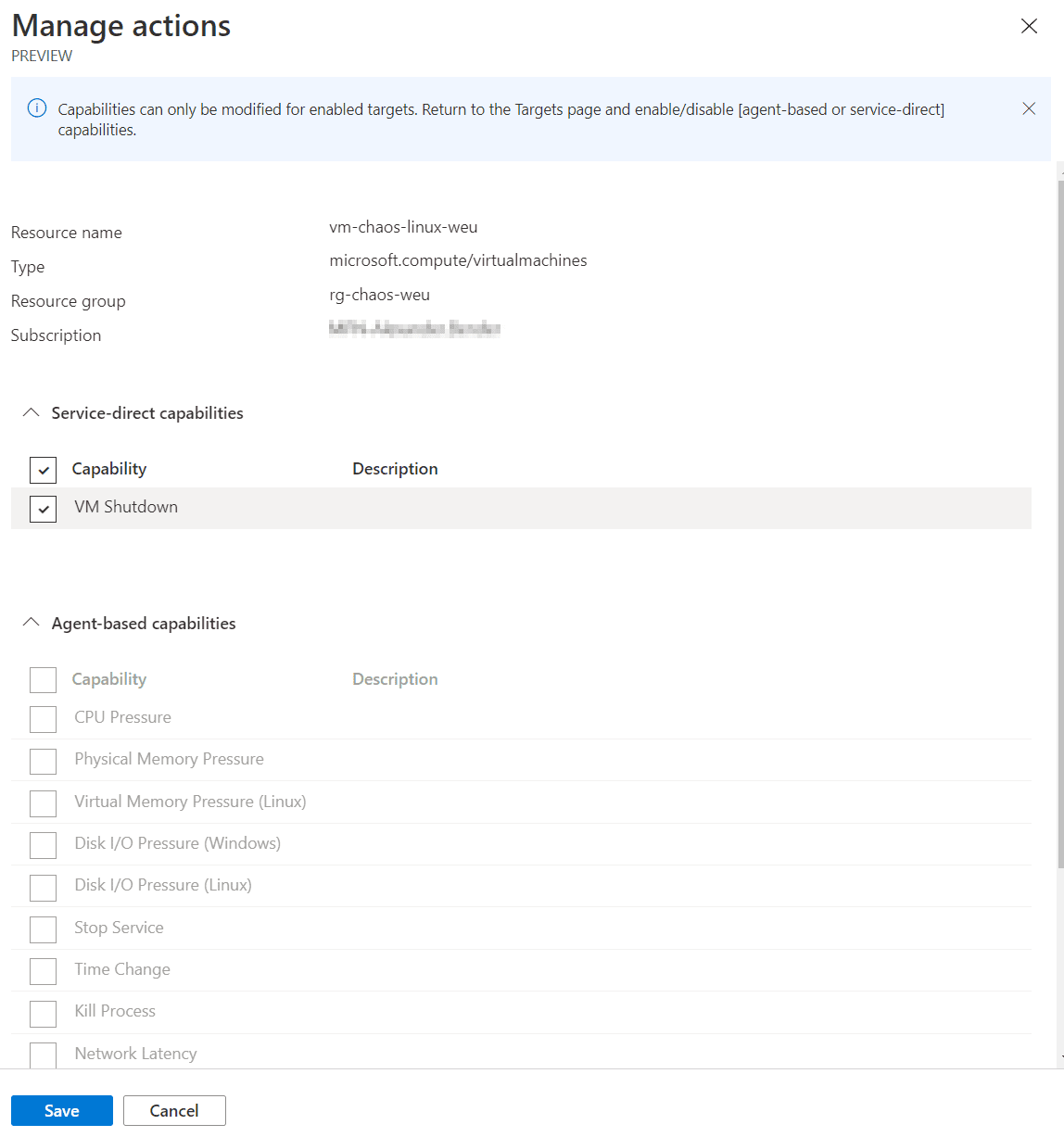
Das Erstellen von Experimenten ist komplett über eine einfache Oberfläche im Azure Portal möglich. Der Ablauf ist aufgeteilt in aufeinanderfolgende Schritte, welche jeweils parallel laufende Zweige beinhalten können. Jeder Zweig enthält die auszuführenden Aktionen. Zusätzlich können die Ziel-Ressourcen noch logisch in “Selectors” gruppiert werden, um sie besser in den Aktionen referenzieren zu können. Dies ist jedoch zum Zeitpunkt des Schreibens dieses Artikels nicht über die Oberfläche möglich.

Übersicht über die Struktur eines Experiments (Quelle: MSDN)
Insgesamt ist die Oberfläche bereits intuitiv nutzbar und ermöglicht das schnelle, einfache Erstellen von Experimenten. Die Unterstützung von Bicep und ARM Templates ermöglicht die Verwaltung von Experimenten in Git, sowie deren Wiederverwendung für mehrere Umgebungen. Das dargestellte Experiment könnte beispielsweise prüfen, wie eine virtuelle Maschine nach einer Downtime mit zusätzlicher Last zurechtkommt. Alternativ könnte man beispielsweise parallel auf redundanten Systemen die CPU-Last erhöhen, während die primären Systeme heruntergefahren werden.
Das Starten des Experiments ist über das Portal und APIs möglich. Gerade bei den ersten Gehversuchen mit Chaos Studio ist wahrscheinlich, dass die Experimente fehlschlagen. Meist ist dies in fehlenden Berechtigungen begründet. Die Fehlermeldungen sind in der Regel sprechend, bei den Agent-basierten Zielen kann es trotzdem etwas Zeit in Anspruch nehmen die Konfiguration korrekt vorzunehmen. Wer nur erste Erfahrungen mit dem Dienst sammeln möchte, kommt mit den Service-basierten Zielen schneller zu ersten Ergebnissen. Ein Experiment lässt sich jederzeit abbrechen und der ursprüngliche Zustand wiederherstellen. Dies gibt zusätzliche Sicherheit um Experimente auf produktive Umgebungen auszuweiten.

Berechtigungsfehler können schnell erkannt werden
Fazit
Wer bisher Ausfallszenarien primär durch manuelles Ein- und Ausschalten von Ressourcen oder einfache Skripte geprüft hat, bekommt mit Azure Chaos Studio ein einfaches Mittel an die Hand um vergleichbare und wiederholbare Tests durchzuführen. Die überschaubare Verfügbarkeit von Fehlerszenarien in der Preview-Phase schränkt die Einsatzfähigkeit jedoch vor allem außerhalb von Microservice-Architekturen stark ein. Vor allem Dienste wie App Service sollten zeitnah hinzugefügt werden. Interessant wird auch, ob gerade bei solchen Diensten Fehlerszenarien ermöglicht werden, welche aktuell nicht manuell zu provozieren sind. Nützliche Funktionen wie die Möglichkeit, Experimente abzubrechen und das System wieder in den Ursprungszustand zu versetzen, geben Chaos Studio insgesamt das Potenzial, ein nützliches Werkzeug für Cloudarchitekturen zu werden.
Wurde Ihr System schon mal auf seine Ausfallsicherheit geprüft? Benötigen Sie Unterstützung bei der Analyse und Prüfung Ihrer kritischen Komponenten? Kontaktieren Sie uns.